Mermru at Leiden University: Lecture Summary

On December 16, 2025, I had the privilege of giving a lunchtime lecture at the Leiden University Centre for Digital Humanities. The discussion focused on the morphological challenges that Ethio-Semitic languages such as Tigrinya and Amharic pose for language pedagogy, linguistic research, and integration with digital technology, and on how Mermru addresses these challenges.
For those who couldn't attend, here is a summary of the lecture.
The Spark: A Question of Structure
The seed for Mermru was planted in 2009 during my Erasmus Mundus studies in Malta. While attempting to encode grammatical rules for a Unification Grammar course, I hit a wall: there were no usable publicly available resources for Tigrinya or Amharic online. This led to a persistent question: Why are our languages so under-documented, and what are their governing rules?.
This curiosity evolved into a commitment to decode the logic of these languages, eventually culminating in Mermru.
The Problem
Ethio-Semitic languages function very differently from the European languages that dominate today’s digital infrastructure. They rely on a root-and-pattern system (non-concatenative morphology), where meaning is generated by interleaving consonantal roots with specific vowel patterns.
In addition, although these languages use a Geʿez-based script, the number and inventory of characters are not fixed, spelling conventions are not fully standardized, and orthographic ambiguity is widespread. One major challenge is the “sixth-order” character, which functions both as a vowel-bearing form and as a bare consonant. This ambiguity creates significant confusion in both writing and digital text processing.
Together, these factors introduce major challenges for research, digital integration and language pedagogy:
1. Rich and Complex Morphology
A single Tigrinya verb root can theoretically generate over 100,000 distinct surface forms, according to some estimates. While a large Tigrinya dictionary may list around 65,000 entries, real-world usage exposes learners and readers to millions of variations.
2. Poor Integration with Digital Technology
Standard search algorithms treat words as unrelated strings. For example, searching for “house” (ገዛ) often fails to retrieve “their houses” (ገዛውቶም), despite their clear morphological relationship. Similarly, a search for ነገሩ will miss far more complex forms such as ከምዝነገሩዎምን.
3. Pedagogical Gaps
Language teaching often falls into the “whole-word trap”, where words are taught as isolated units rather than as manifestations of underlying roots and patterns. Orthographic ambiguity—especially the unmarked sixth-order letter and the widespread absence of gemination marking—further compounds the problem.
For example, Tigrinya-speaking students learning Amharic encounter systematic confusion. In Tigrinya and Tigrinya-medium instruction, words like ለመደ are pronounced lemede, while in Amharic the same form is pronounced lemmede. Since such shared vocabulary is very frequent, this mismatch creates persistent confusion among young students.
These issues contribute to poor reading comprehension and, ultimately, to university graduates who struggle to write even a simple application letter in their mother tongue. They also negatively affect the acquisition of other languages, including English.
The Solution: The Mermru Engine
Mermru is not just a dictionary. It is a rule-based, dynamic linguistic engine. Instead of listing infinite surface words, it models the DNA of the language.
The engine is built around a “Tree of Meaning” concept:
- Roots (the trunk): Atomic root verbs (e.g., በልዐ “to eat”).
- Derived Verbs: Generative rules produce derived root verbs such as ኣብልዐ, ኣብባልዐ, ኣብበላልዐ, በላልዐ, ተበልዐ, ተባልዐ, ተበላልዐ, ኣብላዕልዐ, and ተብላዕልዐ.
- Derived Forms: From atomic and derived verbs, the engine generates:
- Derived nouns and adjectives such as መብልዒ, ምብልላዕ, ብልዒ, በላዕቲ, etc,
- Full inflectional tables categorized by Tense–Aspect–Mood, covering all possible inflections such as ንበልልዕ, ንበልዖ, ይበልዖም, በልዐ
- Additional valid surface forms created through the interaction of inflections and relevant affixes such as ዝበልዐ, ክንበልልዕ
- Additional valid surface forms created through the interaction of inflections and relevant affixes such as ዝበልዐ, ክንበልልዕ
- Derived nouns and adjectives such as መብልዒ, ምብልላዕ, ብልዒ, በላዕቲ, etc,
This architecture makes Mermru bi-directional: it can generate thousands of surface forms from a single root, and it can also relate the complex surface forms back to their underlying components.
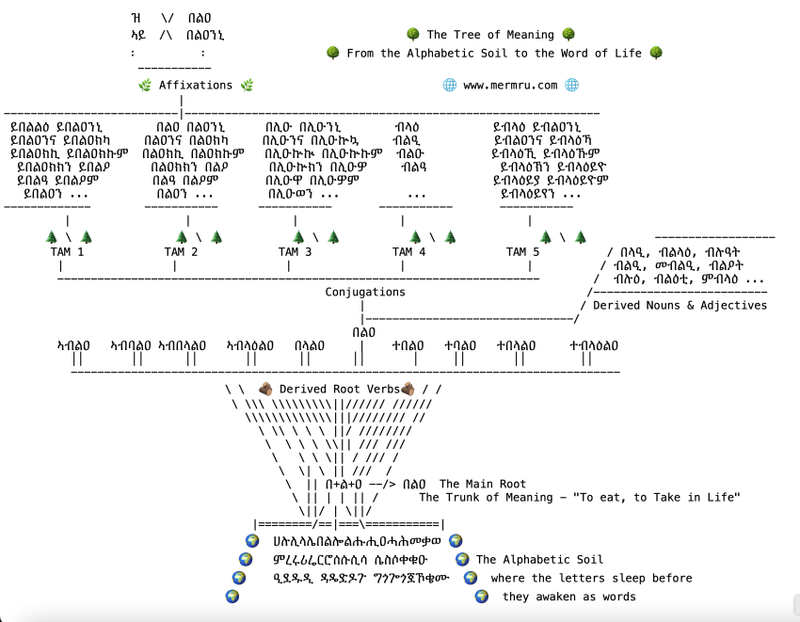
This approach allows Mermru to be bi-directional: it can generate thousands of forms from a single root, but it can also analyze any complex surface word back to its source components.
Applications: From Pedagogy to AI
By modeling the deep structure of Ethio-Semitic languages, Mermru enables progress in three key areas:
Research & Comparative Linguistics
Mermru provides a standardized environment for testing linguistic rules across dialects and languages (Tigrinya, Amharic, Geʿez, etc.). This allows researchers to move beyond impressionistic or faulty comparisons and toward quantitative, rule-based historical and comparative analysis.
Revolutionizing Education
Mermru replaces rote memorization with structural understanding. By visualizing the systematic relationships between words, it helps learners grasp the root-and-pattern nature of the language. This foundation also enables gamified learning experiences that make mastering complex morphology engaging and intuitive.
Digital Tools
Mermru enables the development of long-missing digital tools for Ethio-Semitic languages, including:
- Morphology-aware text search, capable of finding words regardless of prefixes or suffixes
- Proofreading tools, including spellcheckers and grammar checkers that understand morphology
- Machine translation and chatbots, by providing the structured linguistic data needed to improve AI performance
During the lecture, mermru.com was demonstrated through several live examples.
Conclusion
Mermru is more than a linguistic engine modeling the root-and-pattern structure of Ethio-Semitic languages. It is also a proposal for reforming how we write, teach, and digitally process our languages in ways that better reflect spoken reality.
By transforming what has long been a morphological bottleneck into a generative engine, Mermru opens new possibilities for research, education, and innovation. Currently focused on Tigrinya, the model is fully exportable, with Amharic and Geʿez integration on the horizon.
Visit and interact with the linguistic engine at Mermru.